Refresh Model 3 spotted without any side mirrors, and testing new camera locations. Rear window, trunk, side repeaters. In Palo Alto, CA.



Welcome to Tesla Motors Club
Discuss Tesla's Model S, Model 3, Model X, Model Y, Cybertruck, Roadster and More.
Register
Install the app
How to install the app on iOS
You can install our site as a web app on your iOS device by utilizing the Add to Home Screen feature in Safari. Please see this thread for more details on this.
Note: This feature may not be available in some browsers.
-
Want to remove ads? Register an account and login to see fewer ads, and become a Supporting Member to remove almost all ads.
You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
FSD tweets
- Thread starter DanCar
- Start date
-
- Tags
- elon is an ass
Mobileye says FSD E2E approach is doomed to failure.

 www.mobileye.com
www.mobileye.com
Autonomous Decisions: The Bias-Variance Tradeoff in Self-Driving Technology | Mobileye Blog
Monolithic versus Compound AI System in LLMs and Autonomous Driving
12.4 has gone out to employees. 2024.9.5
 www.notateslaapp.com
www.notateslaapp.com
Tesla Releases FSD v12.4: New Vision Attention Monitoring, Improved Strike System With Update 2024.9.5
Tesla has released FSD v12.4 to employees with a new vision-based cabin monitoring system.
www.notateslaapp.com
Last edited:
Another Elon crazy incorrect prediction. Perhaps designed to pump up the stock price. Elon says AGI next year. This prediction will work as well as his 2016 and future year predictions of FSD coming in 2 years.
Tesla twitter account advertising FSD.
diplomat33
Average guy who loves autonomous vehicles
Another Elon crazy incorrect prediction. Perhaps designed to pump up the stock price. Elon says AGI next year. This prediction will work as well as his 2016 and future year predictions of FSD coming in 2 years.
Well, if you really dumb down the definition of AGI, it might be possible to achieve next year.
")
You could ask Elon when the end of the universe will be and......."Next Year"Well, if you really dumb down the definition of AGI, it might be possible to achieve next year.

Ben W
Chess Grandmaster (Supervised)
In 2017 Elon said SpaceX would fly private citizens around the Moon in 2018. He is consistently about 10x too optimistic on short-to-medium-term timeframes.Another Elon crazy incorrect prediction. Perhaps designed to pump up the stock price. Elon says AGI next year. This prediction will work as well as his 2016 and future year predictions of FSD coming in 2 years.
Elon doesn't realize his neural network uses CNNs.
Ben W
Chess Grandmaster (Supervised)
He prefers FoxNewses.Elon doesn't realize his neural network uses CNNs.
A short post on the best architectures for real-time image and video processing.TL;DR: use convolutions with stride or pooling at the low levels, and stick self-attention circuits at higher levels, where feature vectors represent objects.
PS: ready to bet that Tesla FSD uses convolutions (or perhaps more complex *local* operators) at the low levels, combined with more global circuits at higher levels (perhaps using self-attention). Transformers on low-level patch embeddings are a complete waste of electrons.
I'm not saying ViTs are not practical (we use them).
I'm saying they are way too slow and inefficient to be practical for real-time processing of high-resolution images and video.
[Also, @sainingxie's work on ConvNext has shown that they are just as good as ViTs if you do it right. But whatever].
You need at least a few Conv layers with pooling and stride before you stick self-attention circuits.
Self-attention is equivariant to permutations, which is completely nonsensical for low-level image/video processing (having a single strided conv at the front-end to 'patchify' also doesn't make sense).
Global attention is also nonsensical (and not scalable), since correlations are highly local in images and video.
At high level, once features represent objects, then it makes sense to use self-attention circuits: what matters is the relationships and interactions between objects, not their positions.
This type of hybrid architecture was inaugurated by the DETR system by @alcinos26 and collaborators.
As I've said since the DETR work, my favorite family of architectures is conv/stride/pooling at the lower levels, and self-attention circuits at the higher levels.
PS: ready to bet that Tesla FSD uses convolutions (or perhaps more complex *local* operators) at the low levels, combined with more global circuits at higher levels (perhaps using self-attention). Transformers on low-level patch embeddings are a complete waste of electrons.
I'm not saying ViTs are not practical (we use them).
I'm saying they are way too slow and inefficient to be practical for real-time processing of high-resolution images and video.
[Also, @sainingxie's work on ConvNext has shown that they are just as good as ViTs if you do it right. But whatever].
You need at least a few Conv layers with pooling and stride before you stick self-attention circuits.
Self-attention is equivariant to permutations, which is completely nonsensical for low-level image/video processing (having a single strided conv at the front-end to 'patchify' also doesn't make sense).
Global attention is also nonsensical (and not scalable), since correlations are highly local in images and video.
At high level, once features represent objects, then it makes sense to use self-attention circuits: what matters is the relationships and interactions between objects, not their positions.
This type of hybrid architecture was inaugurated by the DETR system by @alcinos26 and collaborators.
As I've said since the DETR work, my favorite family of architectures is conv/stride/pooling at the lower levels, and self-attention circuits at the higher levels.
Poll: Update choice: Spring update or wait for FSD 12.4?
Tesla employee says FSD 12.4 doesn't stay in lane.
Daniel in SD
(supervised)
Had to get rid of all the CNNs…Tesla employee says FSD 12.4 doesn't stay in lane.
Related to the CNN discussion: What is science?

 www.nature.com
www.nature.com
What is science? Tech heavyweights brawl over definition
AI pioneer Yann LeCun and Elon Musk went head-to-head in a debate about modern research that drew thousands of comments.
www.nature.com
diplomat33
Average guy who loves autonomous vehicles
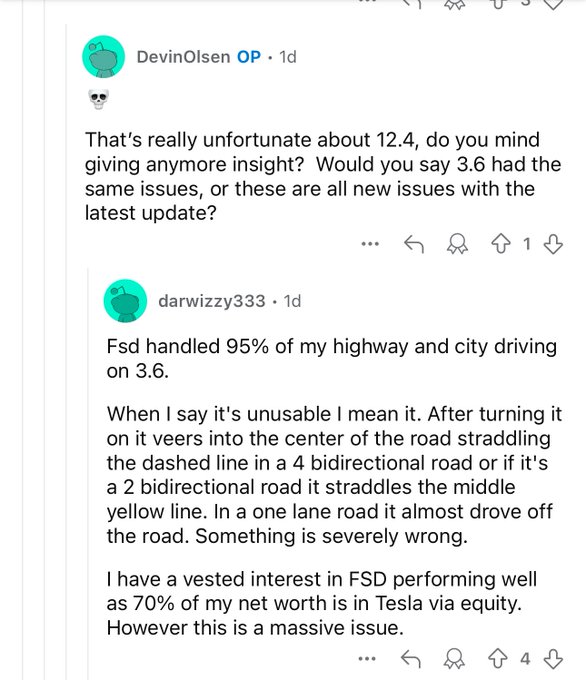
Tesla employee says FSD 12.4 doesn't stay in lane.
It seems that E2E is still prone to the same pattern of improvements, regressions, improvements, regressions, just like the old stack. In my own experience, V12.3.6 has had regressions from V12.2 like the new behavior or wobbling in the lane before making a turn. I guess we will see if the overall trend of V12 is still a faster improvement (ie fewer regressions or regressions are fixed faster).
I'm with Amnon Shashua on this one. He says e2e is doomed to failure.It seems that E2E is still prone to the same pattern of improvements, regressions, improvements, regressions, just like the old stack. In my own experience, V12.3.6 has had regressions from V12.2 like the new behavior or wobbling in the lane before making a turn. I guess we will see if the overall trend of V12 is still a faster improvement (ie fewer regressions or regressions are fixed faster).
Mobileye says FSD E2E approach is doomed to failure.
Autonomous Decisions: The Bias-Variance Tradeoff in Self-Driving Technology | Mobileye Blog
Monolithic versus Compound AI System in LLMs and Autonomous Driving
I don't think it will be too hard for Tesla to switch to an ensemble of neural networks once they realize their predicament. It is also possible that Tesla does have an ensemble currently and not e2e neural network, since Elon is loose with his terminology.
Last edited:
diplomat33
Average guy who loves autonomous vehicles
Tesla employee says FSD 12.4 doesn't stay in lane.
And some more details from the same user:
Similar threads
- Replies
- 226
- Views
- 15K
- Replies
- 106
- Views
- 4K
- Replies
- 3
- Views
- 1K
- Replies
- 5
- Views
- 376